Enterprise
Argentum AI delivers enterprise-scale compute through a single independent partner, uniting power and global capacity into one reliable infrastructure layer without hyperscaler limits.

Global Footprint

15+ Countries Live or Contracted
Data Centers Across 4+ Continents
©2026
15+ Countries Live or Contracted
Data Centers Across 4+ Continents
Enterprise
Argentum AI delivers enterprise-scale compute through a single independent partner, uniting power and global capacity into one reliable infrastructure layer without hyperscaler limits.
One powerful enterprise platform for deterministic global compute capacity.

The new way to scale enterprise compute
Access global GPU and power capacity through a single independent control plane, built for long-term contracts, predictable performance, and hyperscaler-grade execution without lock-in.
Designed for large-scale, multi-site AI deployments where capacity, power, and delivery timelines matter.


Compute capacity is tightening. Power — not GPUs — is now the binding constraint.
As demand accelerates, long-term dependency on a small number of hyperscalers is becoming the default — and the risk.
Beyond the hyperscalers, global GPU and power capacity exists. But it is fragmented, uneven, and impossible to rely on at enterprise scale.
Until now.
Argentum AI turns independent global compute into a single, enterprise-grade infrastructure layer.
Capacity is power-backed, contractually secured, and operated to a common standard — delivered through one accountable partner.
We transform fragmented supply into reliable, production-grade capacity that enterprises can plan, deploy, and scale against with confidence.
Not a marketplace. An enterprise control plane for global compute.
Global power
at enterprise scale

Argentum AI secures enterprise compute capacity against real, available power - not theoretical availability.
We contract, standardize, and operate GPU infrastructure through long-term, enterprise-grade agreements, delivered via a single control plane.
Capacity is allocated deliberately, aligned to workload requirements and timelines, and backed by accountable operations.
Instead of juggling providers, contracts, and availability risk, teams get predictable, power-secured capacity they can plan and scale against with confidence.
When power becomes the constraint, architecture becomes the advantage.
Recent coverage of Argentum AI infrastructure capacity and the enterprise GPU cloud market.

June 24, 2026
SiliconANGLE explores why Wall Street is watching Argentum AI after reported $7.8 billion infrastructure agreements and the company's demand-led financing model.

June 23, 2026
Argentum AI, a private cloud-computing company backed by Super Micro Computer, has secured $7.8 billion in AI infrastructure deals...

May 17, 2026
Andrew Sobko reports that Argentum AI has signed a $2.5 billion data centre deal with cloud and real estate firms. The agreement...

May 15, 2026
May 15: Argentum AI has signed a deal worth around $2.5 billion with cloud gaming firm Boosteroid and real estate company DL Invest...

May 5, 2026
In the world of artificial intelligence and heavy data processing, the GPU is king. However, as AI models become more sophisticated and computationally...

April 29, 2026
San Francisco, CA, USA, April 29th, 2026, Chainwire Argentum AI today signed a landmark $1.5 billion agreement with one of the major...
The cloud isn't the constraint.
Power - and control - are.
Capacity secured against real, available power - not theoretical availability - across global sites.
Contracted capacity aligned to sustained workloads, delivery timelines, and enterprise planning cycles.
Intelligent, real-time allocation across sites - governed by workload requirements, not spot availability.
One operational standard across all providers - covering deployment, monitoring, lifecycle, and support.
Global scale senior lending, providing capital efficient ways to deliver institutional financed solutions.
One contract, one SLA, one accountable counterparty - regardless of how many sites sit underneath.
Inside the Argentum AI
platform
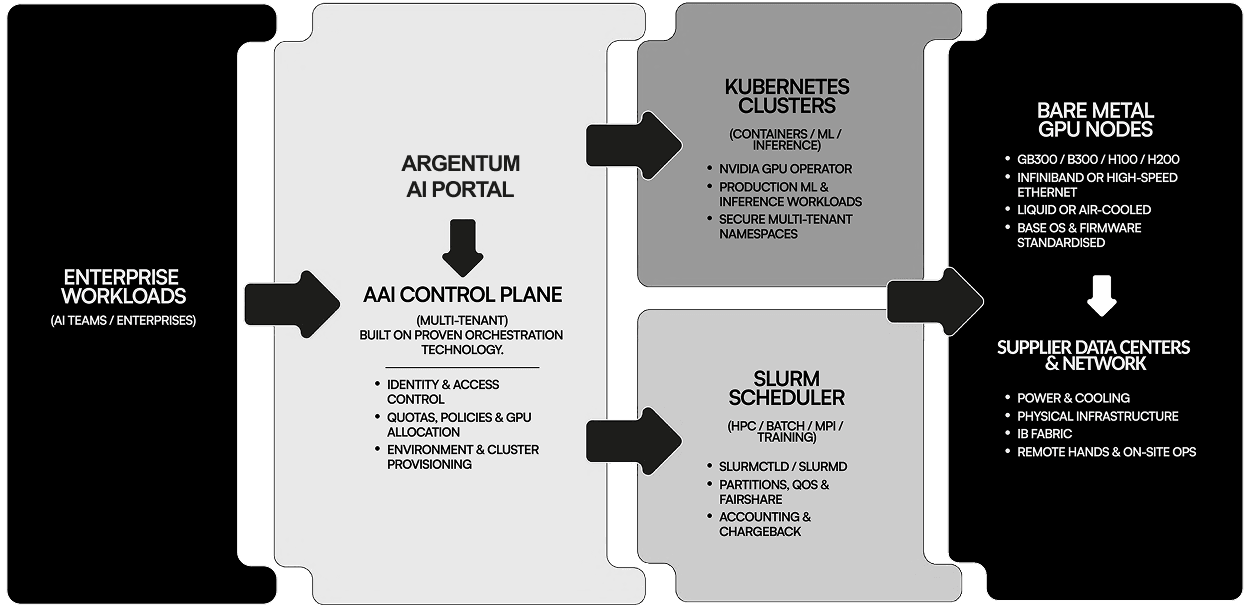
Deterministic capacity. Accountable operations. Enterprise control.
outcomes -> trust
Argentum AI is designed for workloads where failure, contention, or unpredictability is not acceptable.
Capacity is matched deliberately to workload requirements, allocated in real time, and governed by enforceable policies - not best-effort availability.
Enterprises get deterministic performance, workload isolation, and measurable SLAs across the full lifecycle of training, inference, and HPC execution.
capabilities -> proof
Our workloads are supported by a vast global network of underlying infrastructure providers






+95 more
Live supply.
Live demand.
Live contracts.
200,000+ GPUs available now =
200MW of power capacity accessible
Figures reflect active supply under management across multiple contract states.


Capacity is deployed, reserved, or contractually secured across global sites - aligned to delivery timelines and workload requirements.
Deterministic capacity. Accountable operations. Enterprise control.
Argentum AI is designed for workloads where failure, contention, or unpredictability is not acceptable. Capacity is allocated in real time and governed by enforceable policies.
Our workloads are supported by a vast global network of underlying infrastructure providers
+95 more providers
200,000+ GPUs available now = 200MW of power capacity accessible
Figures reflect active supply under management across multiple contract states.
Capacity is deployed, reserved, or contractually secured across global sites - aligned to delivery timelines and workload requirements.
Discuss your capacity requirements with our team
We engage on long-term, production-grade deployments.
Type: Full-time
Type: Full-time
Type: Full-time
Type: Full-time
Type: Full-time
Type: Full-time
Type: Full-time
Type: Full-time
Type: Full-time
Type: Full-time
Type: Full-time
Type: Full-time
Type: Full-time
Type: Full-time
Type: Full-time